Content
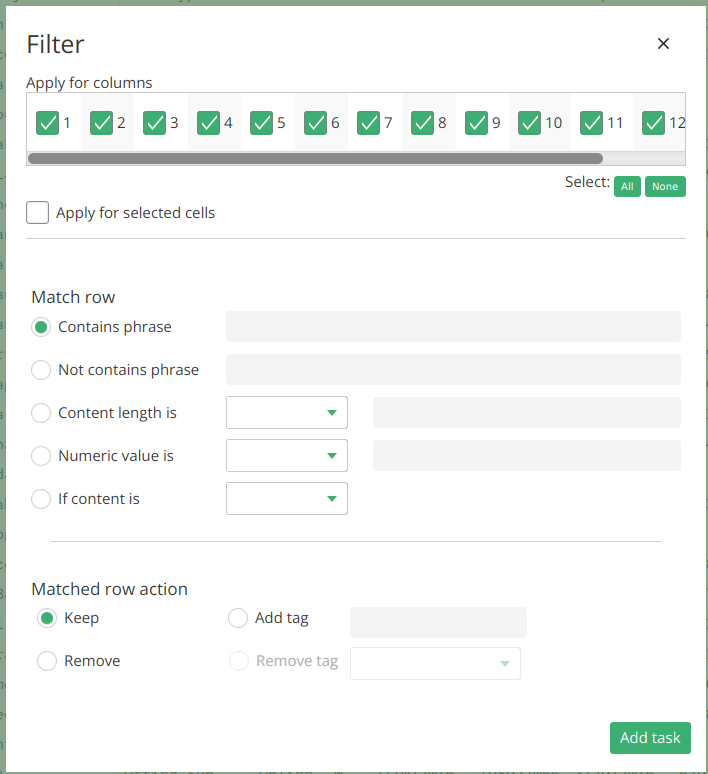
Filter
The filter task is essential for selecting specific rows based on criteria defined within columns. Rows can be selected if a column contains or does not contain a certain value, if the content length is longer or shorter than a specified value, or if the content matches various types such as alphanumeric characters, numeric values, or upper/lower case. Once rows are matched, actions such as keeping them, removing them, tagging them, or removing tags from them can be performed. Read more about tags
Example Usage
Suppose you have a dataset containing customer feedback. Using the filter task, you can select all rows where the “Sentiment” column contains the word “positive,” keeping only the positive feedback for further analysis.
Trim
The trim task is a fundamental operation for cleaning up data by removing leading and trailing white spaces from values in selected columns. It ensures data consistency and improves the accuracy of subsequent analyses, particularly when dealing with unstructured datasets.
Replace
The replace task allows users to substitute specific values within selected columns, facilitating data correction and standardization. It is commonly used to rectify data inconsistencies, update outdated values, or harmonize data representations.
Change Case
The change case task enables users to convert the case of values in selected columns to either lower or upper case. This operation is valuable for ensuring uniformity and consistency in textual data.
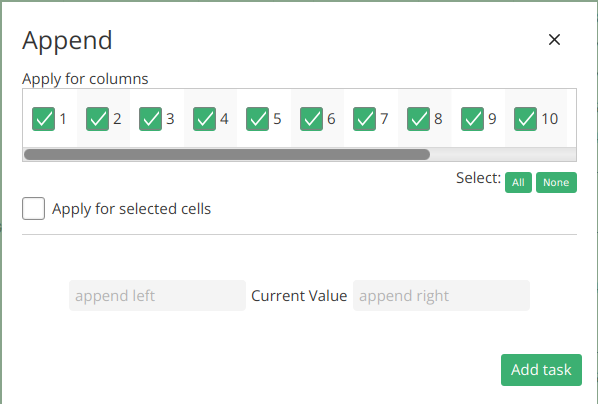
Append
The append task allows users to add text to the beginning or end of values in selected columns. This functionality is useful for appending prefixes or suffixes to data elements.
Example Usage
In a dataset containing product codes, the append task can be utilized to add a prefix indicating the product category, facilitating easier identification and categorization.
Insert
The insert task enables users to insert values into selected columns, including strings from input, random strings, random numbers within a specified range, hashes of column values, or UUID4 values.
Example Usage
In a dataset containing customer IDs, the insert task can be used to generate and insert unique UUID4 values into the “ID” column, ensuring each customer record has a distinct identifier.
Substring
The substring task allows users to extract a portion of the column value based on specified position and length parameters. This functionality is valuable for extracting substrings or segments from textual data.
Math
The math task facilitates basic numeric operations on values in selected columns, such as addition, subtraction, multiplication, and division. This functionality is useful for performing calculations and deriving new insights from numerical data.
Reverse
The reverse task reverses the order of characters in values of the selected column. This operation is helpful for tasks such as reversing strings or sequences.
Date reformat
The date reformat task facilitates the conversion of date formats in values of selected columns. Users provide the current format and the required format, and the task handles the conversion accordingly.
Example Usage
In a dataset containing dates in the “Timestamp” column in the format “YYYY-MM-DD,” the date reformat task can be used to convert them to the format “DD/MM/YYYY” for easier interpretation and analysis.